com.codename1.io.package.html Maven / Gradle / Ivy
Networking, Storage, Filesystem & related API's
The IO package includes all of the main features related to storage and networking with the exception
of {@link com.codename1.db SQL} & XML parsing.
Storage
{@link com.codename1.io.Storage} is accessed via the Storage
class. It is a flat filesystem like interface and contains the ability to list/delete and
write to named storage entries.
The {@link com.codename1.io.Storage} API also provides convenient methods to write objects to
{@link com.codename1.io.Storage} and read them from {@link com.codename1.io.Storage} specifically
readObject & writeObject.
Notice that objects in {@link com.codename1.io.Storage} are deleted when an app is uninstalled but are
retained between application updates.
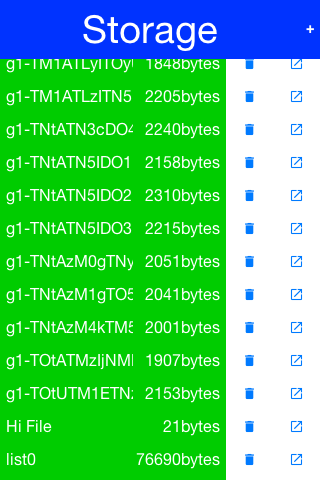
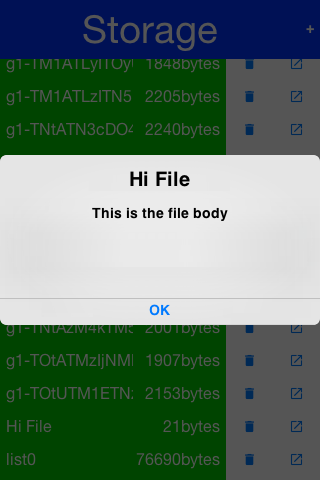
The sample code below demonstrates listing the content of the storage, adding/viewing and
deleting entries within the storage:
The Preferences API
{@link com.codename1.io.Storage} also offers a very simple API in the form of the
{@link com.codename1.io.Preferences}
class. The {@link com.codename1.io.Preferences} class allows developers to store simple variables, strings,
numbers, booleans etc. in storage without writing any storage code. This is a common use case
within applications e.g. you have a server token that you need to store you can store & read it like this:
This gets somewhat confusing with primitive numbers e.g. if you use
Preferences.set("primitiveLongValue", myLongNumber) then invoke
Preferences.get("primitiveLongValue", 0) you might get an exception!
This would happen because the value is physically a Long object but you are
trying to get an Integer. The workaround is to remain consistent and use code
like this Preferences.get("primitiveLongValue", (long)0).
File System
{@link com.codename1.io.FileSystemStorage} provides file system access. It maps to the underlying
OS's file system API providing most of the common operations expected from a file API somewhat in
the vain of java.io.File & java.io.FileInputStream e.g. opening,
renaming, deleting etc.
Notice that the file system API is somewhat platform specific in its behavior. All paths used the API
should be absolute otherwise they are not guaranteed to work.
The main reason java.io.File & java.io.FileInputStream
weren't supported directly has a lot to do with the richness of those two API's. They effectively
allow saving a file anywhere, however mobile devices are far more restrictive and don't allow
apps to see/modify files that are owned by other apps.
File Paths & App Home
All paths in {@link com.codename1.io.FileSystemStorage} are absolute, this simplifies the issue of portability
significantly since the concept of relativity and current working directory aren't very portable.
All URL's use the / as their path separator we try to enforce this behavior even in
Windows.
Directories end with the / character and thus can be easily distinguished by their name.
The {@link com.codename1.io.FileSystemStorage} API provides a getRoots() call to list the root
directories of the file system (you can then "dig in" via the listFiles API). However,
this is confusing and unintuitive for developers.
To simplify the process of creating/reading files we added the getAppHomePath() method.
This method allows us to obtain the path to a directory where files can be stored/read.
We can use this directory to place an image to share as we did in the
share sample.
Warning: A common Android hack is to write files to the SDCard storage to share
them among apps. Android 4.x disabled the ability to write to arbitrary directories on the SDCard
even when the appropriate permission was requested.
A more advanced usage of the {@link com.codename1.io.FileSystemStorage} API can be a
{@link com.codename1.io.FileSystemStorage} Tree:

Storage vs. File System
The question of storage vs. file system is often confusing for novice mobile developers. This embeds
two separate questions:
-
Why are there 2 API's where one would have worked?
-
Which one should I pick?
The main reasons for the 2 API's are technical. Many OS's provide 2 ways of accessing data
specific to the app and this is reflected within the API. E.g. on Android the
{@link com.codename1.io.FileSystemStorage} maps to API's such as java.io.FileInputStream
whereas the {@link com.codename1.io.Storage} maps to Context.openFileInput().
The secondary reason for the two API's is conceptual. {@link com.codename1.io.FileSystemStorage} is
more powerful and in a sense provides more ways to fail, this is compounded by the complex
on-device behavior of the API. {@link com.codename1.io.Storage} is designed to be friendlier to the
uninitiated and more portable.
You should pick {@link com.codename1.io.Storage} unless you have a specific requirement that prevents it.
Some API's such as Capture expect a {@link com.codename1.io.FileSystemStorage} URI
so in those cases this would also be a requirement.
Another case where {@link com.codename1.io.FileSystemStorage} is beneficial is the case of hierarchy or
native API usage. If you need a a directory structure or need to communicate with a native
API the {@link com.codename1.io.FileSystemStorage} approach is usually easier.
Warning: In some OS's the {@link com.codename1.io.FileSystemStorage} API can find the
content of the {@link com.codename1.io.Storage} API. As one is implemented on top of the other. This is
undocumented behavior that can change at any moment!
Network Manager & Connection Request
One of the more common problems in Network programming is spawning a new thread to handle
the network operations. In Codename One this is done seamlessly and becomes unessential
thanks to the {@link com.codename1.io.NetworkManager}.
{@link com.codename1.io.NetworkManager} effectively alleviates the need for managing network threads by
managing the complexity of network threading. The connection request class can be used to
facilitate web service requests when coupled with the JSON/XML parsing capabilities.
To open a connection one needs to use a {@link com.codename1.io.ConnectionRequest}
object, which has some similarities to the networking mechanism in JavaScript but is obviously somewhat more elaborate.
You can send a get request to a URL using something like:
Notice that you can also implement the same thing and much more by avoiding the response
listener code and instead overriding the methods of the {@link com.codename1.io.ConnectionRequest} class
which offers multiple points to override e.g.
Notice that overriding buildRequestBody(OutputStream) will only work for
POST requests and will replace writing the arguments.
Important: You don't need to close the output/input streams passed to the
request methods. They are implicitly cleaned up.
{@link com.codename1.io.NetworkManager} also supports synchronous requests which work in a similar
way to Dialog via the invokeAndBlock call and thus don't block
the EDT illegally. E.g. you can do something like this:
Notice that in this case the addToQueueAndWait method returned after the
connection completed. Also notice that this was totally legal to do on the EDT!
Threading
By default the {@link com.codename1.io.NetworkManager} launches with a single network thread. This is
sufficient for very simple applications that don't do too much networking but if you need to
fetch many images concurrently and perform web services in parallel this might be an issue.
Warning: Once you increase the thread count there is no guarantee of order for your requests. Requests
might not execute in the order with which you added them to the queue!
To update the number of threads use:
All the callbacks in the {@code ConnectionRequest} occur on the network thread and
not on the EDT!
There is one exception to this rule which is the postResponse() method designed
to update the UI after the networking code completes.
Important: Never change the UI from a {@link com.codename1.io.ConnectionRequest}
callback. You can either use a listener on the {@link com.codename1.io.ConnectionRequest}, use
postResponse() (which is the only exception to this rule) or wrap your UI code with
{@link com.codename1.ui.Display#callSerially(java.lang.Runnable)}.
Arguments, Headers & Methods
HTTP/S is a complex protocol that expects complex encoded data for its requests. Codename
One tries to simplify and abstract most of these complexities behind common sense API's while
still providing the full low level access you would expect from such an API.
Arguments
HTTP supports several "request methods", most commonly GET &
POST but also a few others such as HEAD, PUT,
DELETE etc.
Arguments in HTTP are passed differently between GET and POST
methods. That is what the setPost method in Codename One determines, whether
arguments added to the request should be placed using the GET semantics or the
POST semantics.
So if we continue our example from above we can do something like this:
This will implicitly add a get argument with the content of value. Notice that we
don't really care what value is. It's implicitly HTTP encoded based on the get/post semantics.
In this case it will use the get encoding since we passed false to the constructor.
A simpler implementation could do something like this:
This would be almost identical but doesn't provide the convenience for switching back and
forth between GET/POST and it isn't as fluent.
We can skip the encoding in complex cases where server code expects illegal HTTP
characters (this happens) using the addArgumentNoEncoding method. We can
also add multiple arguments with the same key using addArgumentArray.
Methods
As we explained above, the setPost() method allows us to manipulate the
get/post semantics of a request. This implicitly changes the POST
or GET method submitted to the server.
However, if you wish to have finer grained control over the submission process e.g. for making a
HEAD request you can do this with code like:
Headers
When communicating with HTTP servers we often pass data within headers mostly for
authentication/authorization but also to convey various properties.
Some headers are builtin as direct API's e.g. content type is directly exposed within the API
since it's a pretty common use case. We can set the content type of a post request using:
We can also add any arbitrary header type we want, e.g. a very common use case is basic
authorization where the authorization header includes the Base64 encoded user/password
combination as such:
This can be quite tedious to do if you want all requests from your app to use this header.
For this use case you can just use:
Server Headers
Server returned headers are a bit trickier to read. We need to subclass the connection request
and override the readHeaders method e.g.:
Here we can extract the headers one by one to handle complex headers such as cookies,
authentication etc.
Error Handling
As you noticed above practically all of the methods in the ConectionRequest
throw IOException. This allows you to avoid the try/catch
semantics and just let the error propagate up the chain so it can be handled uniformly by
the application.
There are two distinct placed where you can handle a networking error:
-
The {@link com.codename1.io.ConnectionRequest} - by overriding callback methods
-
The {@link com.codename1.io.NetworkManager} error handler
Notice that the {@link com.codename1.io.NetworkManager} error handler takes precedence thus allowing
you to define a global policy for network error handling by consuming errors.
E.g. if I would like to block all network errors from showing anything to the user I could do
something like this:
The error listener is invoked first with the {@link com.codename1.io.NetworkEvent} matching the
error. Consuming the event prevents it from propagating further down the chain into the
{@link com.codename1.io.ConnectionRequest} callbacks.
We can also override the error callbacks of the various types in the request e.g. in the case of a
server error code we can do:
Important: The error callback callback is triggered in the network thread!
As a result it can't access the UI to show a Dialog or anything like that.
Another approach is to use the setFailSilently(true) method on the
{@link com.codename1.io.ConnectionRequest}. This will prevent the
{@link com.codename1.io.ConnectionRequest} from displaying any errors to the user. It's a very
powerful strategy if you use the synchronous version of the API's e.g.:
This code will only work with the synchronous "AndWait" version of the method since the response
code will take a while to return for the non-wait version.
Error Stream
When we get an error code that isn't 200/300 we ignore the result. This is problematic as the
result might contain information we need. E.g. many webservices provide further XML/JSON
based details describing the reason for the error code.
Calling setReadResponseForErrors(true) will trigger a mode where even errors
will receive the readResponse callback with the error stream. This also means
that API's like getData and the listener API's will also work correctly in
case of error.
GZIP
Gzip is a very common compression format based on the lz algorithm, it's used by web servers
around the world to compress data.
Codename One supports {@link com.codename1.io.gzip.GZIPInputStream} and
{@link com.codename1.io.gzip.GZIPOutputStream}, which allow you to compress data
seamlessly into a stream and extract compressed data from a stream. This is very useful and
can be applied to every arbitrary stream.
Codename One also features a {@link com.codename1.io.gzip.GZConnectionRequest}, which
will automatically unzip an HTTP response if it is indeed gzipped. Notice that some devices (iOS)
always request gzip'ed data and always decompress it for us, however in the case of iOS it
doesn't remove the gziped header. The GZConnectionRequest is aware of such
behaviors so its better to use that when connecting to the network (if applicable).
By default GZConnectionRequest doesn't request gzipped data (only unzips it
when its received) but its pretty easy to do so just add the HTTP header
Accept-Encoding: gzip e.g.:
Do the rest as usual and you should have smaller responses from the servers.
File Upload
{@link com.codename1.io.MultipartRequest} tries to simplify the process of uploading a file from
the local device to a remote server.
You can always submit data in the buildRequestBody but this is flaky and has
some limitations in terms of devices/size allowed. HTTP standardized file upload capabilities
thru the multipart request protocol, this is implemented by countless servers and is well
documented. Codename One supports this out of the box.
Since we assume most developers reading this will be familiar with Java here is the way to
implement the multipart upload in the servlet API.
{@link com.codename1.io.MultipartRequest} is a {@link com.codename1.io.ConnectionRequest}
most stuff you expect from there should work. Even addArgument etc.
Parsing
Codename One has several built in parsers for JSON, XML, CSV & Properties formats. You can
use those parsers to read data from the Internet or data that is shipping with your product. E.g. use the
CSV data to setup default values for your application.
All our parsers are designed with simplicity and small distribution size; they don't validate and will fail
in odd ways when faced with broken data. The main logic behind this is that validation takes up CPU
time on the device where CPU is a precious resource.
Parsing CSV
CSV is probably the easiest to use, the "Comma Separated Values" format is just a list of values
separated by commas (or some other character) with new lines to indicate another row in the table.
These usually map well to an Excel spreadsheet or database table and are supported by default in all
spreadsheets.
To parse a CSV just use the
CSVParser class as such:

The data contains a two dimensional array of the CSV content. You can change the delimiter character
by using the {@code CSVParser} constructor that accepts a character.
IMPORTANT: Notice that we used {@link com.codename1.io.CharArrayReader} for
this sample. Normally you would want to use {@link java.util.InputStreamReader} for real world data.
JSON
The JSON ("Java Script Object Notation") format is popular on the web for passing values to/from
webservices since it works so well with JavaScript. Parsing JSON is just as easy but has two
different variations. You can use the
{@link com.codename1.io.JSONParser} class to build a tree of the JSON data as such:
The response is a {@code Map} containing a nested hierarchy of {@code Collection} ({@code java.util.List}),
Strings and numbers to represent the content of the submitted JSON. To extract the data from a specific
path just iterate the {@code Map} keys and recurs into it.
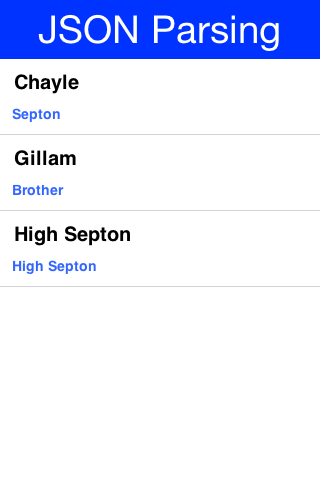
The sample below uses results from an API of ice and fire
that queries structured data about the "Song Of Ice & Fire" book series. Here is a sample result
returned from the API for the query
http://www.anapioficeandfire.com/api/characters?page=5&pageSize=3:
We will place that into a file named "anapioficeandfire.json" in the src directory to make the next
sample simpler:
- The {@code JSONParser} returns a {@code Map} which is great if the root object is a {@code Map}
but in some cases its a list of elements (as is the case above). In this case a special case {@code "root"}
element is created to contain the actual list of elements.
- We rely that the entries are all maps, this might not be the case for every API type.
- Notice that the "titles" and "aliases" entries are both lists of elements. We use {@code java.util.List}
to avoid a clash with {@code com.codename1.ui.List}.
Tip: The structure of the returned map is sometimes unintuitive when looking at the raw JSON. The easiest
thing to do is set a breakpoint on the method and use the inspect variables capability of your IDE to
inspect the returned element hierarchy while writing the code to extract that data
An alternative approach is to use the static data parse() method of the {@code JSONParser} class and
implement a callback parser e.g.: {@code JSONParser.parse(reader, callback);}
Notice that a static version of the method is used! The callback object is an instance of the
{@code JSONParseCallback} interface, which includes multiple methods. These methods are invoked
by the parser to indicate internal parser states, this is similar to the way traditional XML SAX event
parsers work.
XML Parsing
The {@link com.codename1.xml.XMLParser} started its life as an HTML parser built for displaying
mobile HTML. That usage has since been deprecated but the parser can still parse many HTML
pages and is very "loose" in terms of verification. This is both good and bad as the parser will work
with invalid data without complaining.
The simplest usage of {@link com.codename1.xml.XMLParser} looks a bit like this:
The {@link com.codename1.xml.Element} contains children and attributes. It represents a tag within the
XML document and even the root document itself. You can iterate over the XML tree to extract the
data from within the XML file.
We have a great sample of working with {@code XMLParser} in the
{@link com.codename1.ui.tree.Tree} class.
XPath Processing
Codename One ships with support to a subset of XPath processing, you can read more about it in
the {@link com.codename1.processing processing package docs}.
Externalizable Objects
Codename One provides the {@link com.codename1.io.Externalizable} interface, which is similar
to the Java SE {@link com.codename1.io.Externalizable} interface.
This interface allows an object to declare itself as {@link com.codename1.io.Externalizable} for
serialization (so an object can be stored in a file/storage or sent over the network). However, due to the
lack of reflection and use of obfuscation these objects must be registered with the
{@link com.codename1.io.Util} class.
Codename One doesn't support the Java SE Serialization API due to the size issues and
complexities related to obfuscation.
The major objects that are supported by default in the Codename One
{@link com.codename1.io.Externalizable} are:
String, Collection, Map, ArrayList,
HashMap, Vector, Hashtable,
Integer, Double, Float, Byte,
Short, Long, Character, Boolean,
Object[], byte[], int[], float[],
long[], double[].
Externalizing an object such as h below should work just fine:
However, notice that some things aren't polymorphic e.g. if we will externalize a
String[] we will get back an Object[] since String
arrays aren't detected by the implementation.
Important: The externalization process caches objects so the app will seem to
work and only fail on restart!
Implementing the {@link com.codename1.io.Externalizable} interface is only important when we
want to store a proprietary object. In this case we must register the object with the
com.codename1.io.Util class so the externalization algorithm will be able to
recognize it by name by invoking:
You should do this early on in the app e.g. in the init(Object) but you shouldn't do
it in a static initializer within the object as that might never be invoked!
An {@link com.codename1.io.Externalizable} object must have a
default public constructor and must implement the following 4 methods:
The getVersion() method returns the current version of the object allowing the
stored data to change its structure in the future (the version is then passed when internalizing
the object). The object id is a String uniquely representing the object;
it usually corresponds to the class name (in the example above the Unique Name should be
MyClass).
Warning: It's a common mistake to use getClass().getName()
to implement getObjectId() and it would seem to work in the
simulator. This isn't the case though!
Since devices obfuscate the class names this becomes a problem as data is stored in a random
name that changes with every release.
Developers need to write the data of the object in the externalize method using the methods in the
data output stream and read the data of the object in the internalize method e.g.:
Since strings might be null sometimes we also included convenience methods to implement such
externalization. This effectively writes a boolean before writing the UTF to indicate whether the string
is null:
Assuming we added a new date field to the object we can do the following. Notice that a
Date is really a long value in Java that can be null.
For completeness the full class is presented below:
Notice that we only need to check for compatibility during the reading process as the writing
process always writes the latest version of the data.