rx.internal.operators.OperatorMerge Maven / Gradle / Ivy
Show all versions of rxjava-core Show documentation
/**
* Copyright 2014 Netflix, Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package rx.internal.operators;
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
import java.util.concurrent.atomic.AtomicLongFieldUpdater;
import rx.Observable;
import rx.Observable.Operator;
import rx.Producer;
import rx.Subscriber;
import rx.exceptions.CompositeException;
import rx.exceptions.MissingBackpressureException;
import rx.exceptions.OnErrorThrowable;
import rx.functions.Func1;
import rx.internal.util.RxRingBuffer;
import rx.internal.util.ScalarSynchronousObservable;
import rx.internal.util.SubscriptionIndexedRingBuffer;
/**
* Flattens a list of {@link Observable}s into one {@code Observable}, without any transformation.
*
* 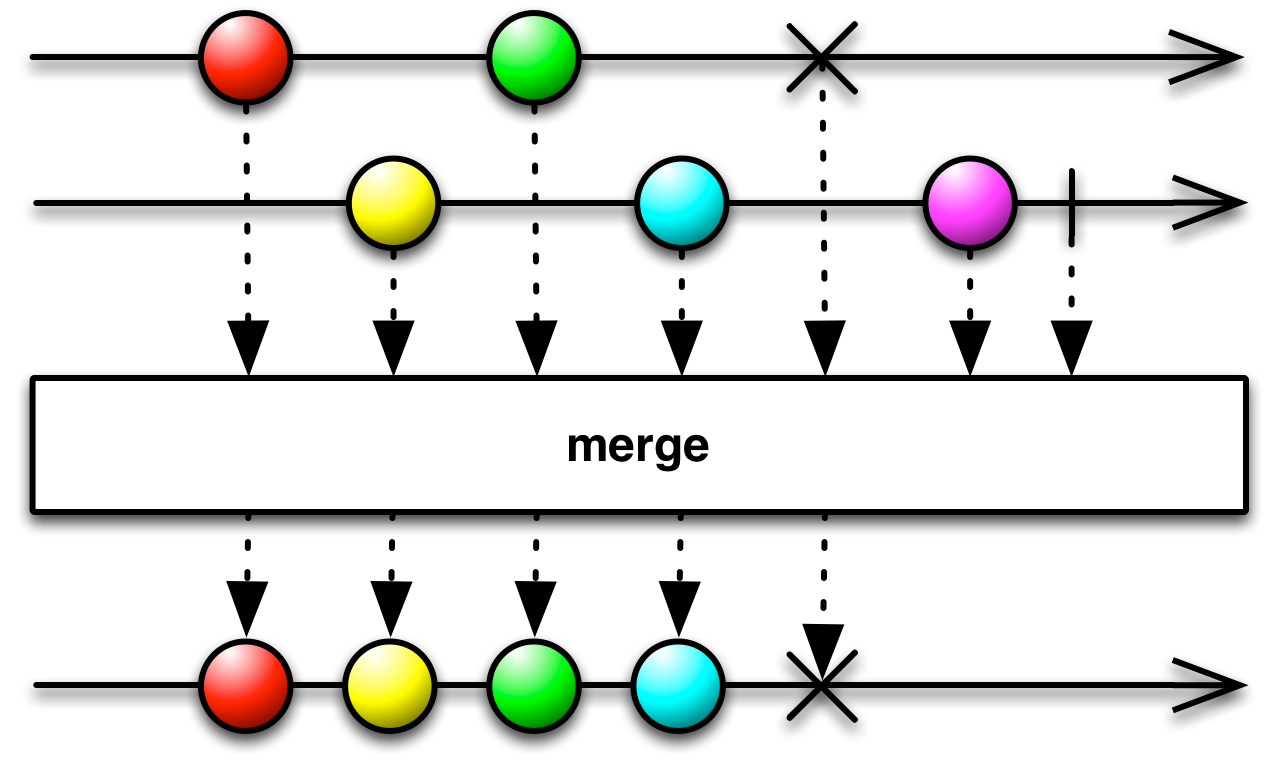 *
*
* You can combine the items emitted by multiple {@code Observable}s so that they act like a single {@code Observable}, by using the merge operation.
*
* @param
* the type of the items emitted by both the source and merged {@code Observable}s
*/
public class OperatorMerge implements Operator> {
/*
* benjchristensen => This class is complex and I'm not a fan of it despite writing it. I want to give some background
* as to why for anyone who wants to try and help improve it.
*
* One of my first implementations that added backpressure support (Producer.request) was fairly elegant and used a simple
* queue draining approach. It was simple to understand as all onNext were added to their queues, then a single winner
* would drain the queues, similar to observeOn. It killed the Netflix API when I canaried it. There were two problems:
* (1) performance and (2) object allocation overhead causing massive GC pressure. Remember that merge is one of the most
* used operators (mostly due to flatmap) and is therefore critical to and a limiter of performance in any application.
*
* All subsequent work on this class and the various fast-paths and branches within it have been to achieve the needed functionality
* while reducing or eliminating object allocation and keeping performance acceptable.
*
* This has meant adopting strategies such as:
*
* - ring buffers instead of growable queues
* - object pooling
* - skipping request logic when downstream does not need backpressure
* - ScalarValueQueue for optimizing synchronous single-value Observables
* - adopting data structures that use Unsafe (and gating them based on environment so non-Oracle JVMs still work)
*
* It has definitely increased the complexity and maintenance cost of this class, but the performance gains have been significant.
*
* The biggest cost of the increased complexity is concurrency bugs and reasoning through what's going on.
*
* I'd love to have contributions that improve this class, but keep in mind the performance and GC pressure.
* The benchmarks I use are in the JMH OperatorMergePerf class. GC memory pressure is tested using Java Flight Recorder
* to track object allocation.
*
* TODO There is still a known concurrency bug somewhere either in this class, in SubscriptionIndexedRingBuffer or their relationship.
* See https://github.com/Netflix/RxJava/issues/1420 for more information on this.
*/
public OperatorMerge() {
this.delayErrors = false;
}
public OperatorMerge(boolean delayErrors) {
this.delayErrors = delayErrors;
}
private final boolean delayErrors;
@Override
public Subscriber> call(final Subscriber child) {
return new MergeSubscriber(child, delayErrors);
}
private static final class MergeSubscriber extends Subscriber> {
final NotificationLite on = NotificationLite.instance();
final Subscriber actual;
private final MergeProducer mergeProducer;
private int wip;
private boolean completed;
private final boolean delayErrors;
private ConcurrentLinkedQueue exceptions;
private volatile SubscriptionIndexedRingBuffer> childrenSubscribers;
private RxRingBuffer scalarValueQueue = null;
/* protected by lock on MergeSubscriber instance */
private int missedEmitting = 0;
private boolean emitLock = false;
/**
* Using synchronized(this) for `emitLock` instead of ReentrantLock or AtomicInteger is faster when there is no contention.
*
* {@code
* Using ReentrantLock:
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 44185.294 1295.565 ops/s
*
* Using synchronized(this):
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 79715.981 3704.486 ops/s
*
* Still slower though than allowing concurrency:
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 149331.046 4851.290 ops/s
* }
*/
public MergeSubscriber(Subscriber actual, boolean delayErrors) {
super(actual);
this.actual = actual;
this.mergeProducer = new MergeProducer(this);
this.delayErrors = delayErrors;
// decoupled the subscription chain because we need to decouple and control backpressure
actual.add(this);
actual.setProducer(mergeProducer);
}
@Override
public void onStart() {
// we request backpressure so we can handle long-running Observables that are enqueueing, such as flatMap use cases
// we decouple the Producer chain while keeping the Subscription chain together (perf benefit) via super(actual)
request(RxRingBuffer.SIZE);
}
/*
* This is expected to be executed sequentially as per the Rx contract or it will not work.
*/
@Override
public void onNext(Observable t) {
if (t instanceof ScalarSynchronousObservable) {
handleScalarSynchronousObservable((ScalarSynchronousObservable)t);
} else {
if (t == null || isUnsubscribed()) {
return;
}
synchronized (this) {
// synchronized here because `wip` can be concurrently changed by children Observables
wip++;
}
handleNewSource(t);
}
}
private void handleNewSource(Observable t) {
if (childrenSubscribers == null) {
// lazily create this only if we receive Observables we need to subscribe to
childrenSubscribers = new SubscriptionIndexedRingBuffer>();
add(childrenSubscribers);
}
MergeProducer producerIfNeeded = null;
// if we have received a request then we need to respect it, otherwise we fast-path
if (mergeProducer.requested != Long.MAX_VALUE) {
/**
* {@code
* With this optimization:
*
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 57100.080 4686.331 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000000 thrpt 5 60.875 1.622 ops/s
*
* Without this optimization:
*
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 29863.945 1858.002 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000000 thrpt 5 30.516 1.087 ops/s
* }
*/
producerIfNeeded = mergeProducer;
}
InnerSubscriber i = new InnerSubscriber(this, producerIfNeeded);
i.sindex = childrenSubscribers.add(i);
t.unsafeSubscribe(i);
request(1);
}
private void handleScalarSynchronousObservable(ScalarSynchronousObservable t) {
// fast-path for scalar, synchronous values such as Observable.from(int)
/**
* Without this optimization:
*
* {@code
* Benchmark (size) Mode Samples Score Score error Units
* r.o.OperatorMergePerf.oneStreamOfNthatMergesIn1 1 thrpt 5 2,418,452.409 130572.665 ops/s
* r.o.OperatorMergePerf.oneStreamOfNthatMergesIn1 1000 thrpt 5 5,690.456 94.958 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000000 thrpt 5 takes too long
*
* With this optimization:
*
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1 thrpt 5 5,475,300.198 156741.334 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 68,932.278 1311.023 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000000 thrpt 5 64.405 0.611 ops/s
* }
*
*/
if (mergeProducer.requested == Long.MAX_VALUE) {
handleScalarSynchronousObservableWithoutRequestLimits(t);
} else {
handleScalarSynchronousObservableWithRequestLimits(t);
}
}
private void handleScalarSynchronousObservableWithoutRequestLimits(ScalarSynchronousObservable t) {
T value = t.get();
if (getEmitLock()) {
try {
actual.onNext(value);
return;
} finally {
if (releaseEmitLock()) {
drainQueuesIfNeeded();
}
request(1);
}
} else {
initScalarValueQueueIfNeeded();
try {
scalarValueQueue.onNext(value);
} catch (MissingBackpressureException e) {
onError(e);
}
return;
}
}
private void handleScalarSynchronousObservableWithRequestLimits(ScalarSynchronousObservable t) {
if (getEmitLock()) {
boolean emitted = false;
try {
long r = mergeProducer.requested;
if (r > 0) {
emitted = true;
actual.onNext(t.get());
MergeProducer.REQUESTED.decrementAndGet(mergeProducer);
// we handle this Observable without ever incrementing the wip or touching other machinery so just return here
return;
}
} finally {
if (releaseEmitLock()) {
drainQueuesIfNeeded();
}
if (emitted) {
request(1);
}
}
}
// if we didn't return above we need to enqueue
// enqueue the values for later delivery
initScalarValueQueueIfNeeded();
try {
scalarValueQueue.onNext(t.get());
} catch (MissingBackpressureException e) {
onError(e);
}
}
private void initScalarValueQueueIfNeeded() {
if (scalarValueQueue == null) {
scalarValueQueue = RxRingBuffer.getSpmcInstance();
add(scalarValueQueue);
}
}
private synchronized boolean releaseEmitLock() {
emitLock = false;
if (missedEmitting == 0) {
return false;
} else {
return true;
}
}
private synchronized boolean getEmitLock() {
if (emitLock) {
missedEmitting++;
return false;
} else {
emitLock = true;
missedEmitting = 0;
return true;
}
}
private boolean drainQueuesIfNeeded() {
while (true) {
if (getEmitLock()) {
int emitted = 0;
try {
emitted = drainScalarValueQueue();
drainChildrenQueues();
} finally {
boolean moreToDrain = releaseEmitLock();
// request outside of lock
request(emitted);
if (!moreToDrain) {
return true;
}
// otherwise we'll loop and get whatever was added
}
} else {
return false;
}
}
}
int lastDrainedIndex = 0;
/**
* ONLY call when holding the EmitLock.
*/
private void drainChildrenQueues() {
if (childrenSubscribers != null) {
lastDrainedIndex = childrenSubscribers.forEach(DRAIN_ACTION, lastDrainedIndex);
}
}
/**
* ONLY call when holding the EmitLock.
*/
private int drainScalarValueQueue() {
if (scalarValueQueue != null) {
long r = mergeProducer.requested;
int emittedWhileDraining = 0;
if (r < 0) {
// drain it all
Object o = null;
while ((o = scalarValueQueue.poll()) != null) {
on.accept(actual, o);
emittedWhileDraining++;
}
} else if (r > 0) {
// drain what was requested
long toEmit = r;
for (int i = 0; i < toEmit; i++) {
Object o = scalarValueQueue.poll();
if (o == null) {
break;
} else {
on.accept(actual, o);
emittedWhileDraining++;
}
}
// decrement the number we emitted from outstanding requests
MergeProducer.REQUESTED.getAndAdd(mergeProducer, -emittedWhileDraining);
}
return emittedWhileDraining;
}
return 0;
}
final Func1, Boolean> DRAIN_ACTION = new Func1, Boolean>() {
@Override
public Boolean call(InnerSubscriber s) {
if (s.q != null) {
long r = mergeProducer.requested;
int emitted = 0;
emitted += s.drainQueue();
if (emitted > 0) {
/*
* `s.emitted` is not volatile (because of performance impact of making it so shown by JMH tests)
* but `emitted` can ONLY be touched by the thread holding the `emitLock` which we're currently inside.
*
* Entering and leaving the emitLock flushes all values so this is visible to us.
*/
emitted += s.emitted;
// TODO we may want to store this in s.emitted and only request if above batch
// reset this since we have requested them all
s.emitted = 0;
s.requestMore(emitted);
}
if (emitted == r) {
// we emitted as many as were requested so stop the forEach loop
return Boolean.FALSE;
}
}
return Boolean.TRUE;
}
};
@Override
public void onError(Throwable e) {
if (delayErrors) {
synchronized (this) {
if (exceptions == null) {
exceptions = new ConcurrentLinkedQueue();
}
}
exceptions.add(e);
boolean sendOnComplete = false;
synchronized (this) {
wip--;
if ((wip == 0 && completed) || (wip < 0)) {
sendOnComplete = true;
}
}
if (sendOnComplete) {
drainAndComplete();
}
} else {
actual.onError(e);
}
}
@Override
public void onCompleted() {
boolean c = false;
synchronized (this) {
completed = true;
if (wip == 0) {
c = true;
}
}
if (c) {
// complete outside of lock
drainAndComplete();
}
}
void completeInner(InnerSubscriber s) {
boolean sendOnComplete = false;
synchronized (this) {
wip--;
if (wip == 0 && completed) {
sendOnComplete = true;
}
}
childrenSubscribers.remove(s.sindex);
if (sendOnComplete) {
drainAndComplete();
}
}
private void drainAndComplete() {
drainQueuesIfNeeded(); // TODO need to confirm whether this is needed or not
if (delayErrors) {
Queue es = null;
synchronized (this) {
es = exceptions;
}
if (es != null) {
if (es.isEmpty()) {
actual.onCompleted();
} else if (es.size() == 1) {
actual.onError(es.poll());
} else {
actual.onError(new CompositeException(es));
}
} else {
actual.onCompleted();
}
} else {
actual.onCompleted();
}
}
}
private static final class MergeProducer implements Producer {
private final MergeSubscriber ms;
public MergeProducer(MergeSubscriber ms) {
this.ms = ms;
}
private volatile long requested = 0;
@SuppressWarnings("rawtypes")
static final AtomicLongFieldUpdater REQUESTED = AtomicLongFieldUpdater.newUpdater(MergeProducer.class, "requested");
@Override
public void request(long n) {
if (requested == Long.MAX_VALUE) {
return;
}
if (n == Long.MAX_VALUE) {
requested = Long.MAX_VALUE;
} else {
REQUESTED.getAndAdd(this, n);
ms.drainQueuesIfNeeded();
}
}
}
private static final class InnerSubscriber extends Subscriber {
public int sindex;
final MergeSubscriber parentSubscriber;
final MergeProducer producer;
/** Make sure the inner termination events are delivered only once. */
volatile int terminated;
@SuppressWarnings("rawtypes")
static final AtomicIntegerFieldUpdater ONCE_TERMINATED = AtomicIntegerFieldUpdater.newUpdater(InnerSubscriber.class, "terminated");
private final RxRingBuffer q = RxRingBuffer.getSpmcInstance();
/* protected by emitLock */
int emitted = 0;
final int THRESHOLD = (int) (q.capacity() * 0.7);
public InnerSubscriber(MergeSubscriber parent, MergeProducer producer) {
this.parentSubscriber = parent;
this.producer = producer;
add(q);
request(q.capacity());
}
@Override
public void onNext(T t) {
emit(t, false);
}
@Override
public void onError(Throwable e) {
// it doesn't go through queues, it immediately onErrors and tears everything down
if (ONCE_TERMINATED.compareAndSet(this, 0, 1)) {
parentSubscriber.onError(e);
}
}
@Override
public void onCompleted() {
if (ONCE_TERMINATED.compareAndSet(this, 0, 1)) {
emit(null, true);
}
}
public void requestMore(long n) {
request(n);
}
private void emit(T t, boolean complete) {
boolean drain = false;
boolean enqueue = true;
/**
* This optimization to skip the queue is messy ... but it makes a big difference in performance when merging a single stream
* with many values, or many intermittent streams without contention. It doesn't make much of a difference if there is contention.
*
* Below are some of the relevant benchmarks to show the difference.
*
* {@code
* With this fast-path:
*
* Benchmark (size) Mode Samples Score Score error Units
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1 thrpt 5 5344143.680 393484.592 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 83582.662 4293.755 ops/s +++
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000000 thrpt 5 73.889 4.477 ops/s +++
*
* r.o.OperatorMergePerf.mergeNSyncStreamsOfN 1 thrpt 5 5799265.333 199205.296 ops/s +
* r.o.OperatorMergePerf.mergeNSyncStreamsOfN 1000 thrpt 5 62.655 2.521 ops/s +++
*
* r.o.OperatorMergePerf.mergeTwoAsyncStreamsOfN 1 thrpt 5 76925.616 4909.174 ops/s
* r.o.OperatorMergePerf.mergeTwoAsyncStreamsOfN 1000 thrpt 5 3634.977 242.469 ops/s
*
* Without:
*
* Benchmark (size) Mode Samples Score Score error Units
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1 thrpt 5 5099295.678 159539.842 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 18196.671 10053.298 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000000 thrpt 5 19.184 1.028 ops/s
*
* r.o.OperatorMergePerf.mergeNSyncStreamsOfN 1 thrpt 5 5591612.719 591821.763 ops/s
* r.o.OperatorMergePerf.mergeNSyncStreamsOfN 1000 thrpt 5 21.018 3.251 ops/s
*
* r.o.OperatorMergePerf.mergeTwoAsyncStreamsOfN 1 thrpt 5 72692.073 18395.031 ops/s
* r.o.OperatorMergePerf.mergeTwoAsyncStreamsOfN 1000 thrpt 5 4379.093 386.368 ops/s
* }
*
* It looks like it may cause a slowdown in highly contended cases (like 'mergeTwoAsyncStreamsOfN' above) as instead of just
* putting in the queue, it attempts to get the lock. We are optimizing for the non-contended case.
*/
if (parentSubscriber.getEmitLock()) {
enqueue = false;
try {
// drain the queue if there is anything in it before emitting the current value
emitted += drainQueue();
// }
if (producer == null) {
// no backpressure requested
if (complete) {
parentSubscriber.completeInner(this);
} else {
try {
parentSubscriber.actual.onNext(t);
} catch (Throwable e) {
// special error handling due to complexity of merge
onError(OnErrorThrowable.addValueAsLastCause(e, t));
}
emitted++;
}
} else {
// this needs to check q.count() as draining above may not have drained the full queue
// perf tests show this to be okay, though different queue implementations could perform poorly with this
if (producer.requested > 0 && q.count() == 0) {
if (complete) {
parentSubscriber.completeInner(this);
} else {
try {
parentSubscriber.actual.onNext(t);
} catch (Throwable e) {
// special error handling due to complexity of merge
onError(OnErrorThrowable.addValueAsLastCause(e, t));
}
emitted++;
MergeProducer.REQUESTED.decrementAndGet(producer);
}
} else {
// no requests available, so enqueue it
enqueue = true;
}
}
} finally {
drain = parentSubscriber.releaseEmitLock();
}
if (emitted > THRESHOLD) {
// this is for batching requests when we're in a use case that isn't queueing, always fast-pathing the onNext
/**
* {@code
* Without this batching:
*
* Benchmark (size) Mode Samples Score Score error Units
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1 thrpt 5 5060743.715 100445.513 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 36606.582 1610.582 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000000 thrpt 5 38.476 0.973 ops/s
*
* With this batching:
*
* Benchmark (size) Mode Samples Score Score error Units
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1 thrpt 5 5367945.738 262740.137 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000 thrpt 5 62703.930 8496.036 ops/s
* r.o.OperatorMergePerf.merge1SyncStreamOfN 1000000 thrpt 5 72.711 3.746 ops/s
*}
*/
request(emitted);
// we are modifying this outside of the emit lock ... but this can be considered a "lazySet"
// and it will be flushed before anything else touches it because the emitLock will be obtained
// before any other usage of it
emitted = 0;
}
}
if (enqueue) {
enqueue(t, complete);
drain = true;
}
if (drain) {
/**
* This extra check for whether to call drain is ugly, but it helps:
* {@code
* Without:
* r.o.OperatorMergePerf.mergeNSyncStreamsOfN 1000 thrpt 5 61.812 1.455 ops/s
*
* With:
* r.o.OperatorMergePerf.mergeNSyncStreamsOfN 1000 thrpt 5 78.795 1.766 ops/s
* }
*/
parentSubscriber.drainQueuesIfNeeded();
}
}
private void enqueue(T t, boolean complete) {
try {
if (complete) {
q.onCompleted();
} else {
q.onNext(t);
}
} catch (MissingBackpressureException e) {
onError(e);
}
}
private int drainRequested() {
int emitted = 0;
// drain what was requested
long toEmit = producer.requested;
Object o;
for (int i = 0; i < toEmit; i++) {
o = q.poll();
if (o == null) {
// no more items
break;
} else if (q.isCompleted(o)) {
parentSubscriber.completeInner(this);
} else {
try {
if (!q.accept(o, parentSubscriber.actual)) {
emitted++;
}
} catch (Throwable e) {
// special error handling due to complexity of merge
onError(OnErrorThrowable.addValueAsLastCause(e, o));
}
}
}
// decrement the number we emitted from outstanding requests
MergeProducer.REQUESTED.getAndAdd(producer, -emitted);
return emitted;
}
private int drainAll() {
int emitted = 0;
// drain it all
Object o;
while ((o = q.poll()) != null) {
if (q.isCompleted(o)) {
parentSubscriber.completeInner(this);
} else {
try {
if (!q.accept(o, parentSubscriber.actual)) {
emitted++;
}
} catch (Throwable e) {
// special error handling due to complexity of merge
onError(OnErrorThrowable.addValueAsLastCause(e, o));
}
}
}
return emitted;
}
private int drainQueue() {
if (producer != null) {
return drainRequested();
} else {
return drainAll();
}
}
}
}